
El análisis predictivo se ha convertido en un elemento crucial para las empresas que desean aprovechar al máximo sus datos para optimizar sus procesos operativos y mejorar su eficiencia y eficacia. Este método se basa en el análisis de datos históricos que, mediante el uso de algoritmos estadísticos avanzados y técnicas de aprendizaje automático, identifica patrones y tendencias útiles para predecir acontecimientos futuros.
Con la evolución de la tecnología, ahora es posible procesar grandes volúmenes de datos con precisión y rapidez. Como parte de Var Group Data Science for Analytics, apoyamos a numerosas empresas que adoptan esta metodología, también conocida como Forecasting, para obtener una importante ventaja competitiva. Se trata de una herramienta clave para anticiparse a las tendencias del mercado y dirigir de forma proactiva las decisiones empresariales. El análisis predictivo encuentra aplicación en diversos sectores, como el comercio electrónico, la sanidad, el comercio minorista y las finanzas, lo que demuestra su versatilidad y su valor intersectorial.
En este artículo, examinaremos las distintas herramientas de análisis predictivo que ofrece Power BI.
¿Se pueden realizar análisis predictivos con Power BI?
Power BI no sólo se limita al análisis de datos actuales, sino que también puede utilizarse en la predicción de tendencias futuras. Existen principalmente dos herramientas con las que realizar análisis predictivos en Power BI:
- Análisis de previsiones temporales en Power BI: Power BI pone a disposición de los usuarios un conjunto de herramientas de análisis temporal para explorar tendencias y tendencias en datos históricos y realizar previsiones basadas en modelos predictivos. La funcionalidad de predicción es accesible e intuitiva para los usuarios, ya que les permite modificar parámetros de predicción como la duración, la estacionalidad y el intervalo de confianza directamente desde el menú gráfico del panel de vistas.
- Extensiones integradoras para el análisis predictivo: Power BI es capaz de añadir y utilizar internamente herramientas de análisis como R y Python, lo que permite a los usuarios explotar las bibliotecas de estos lenguajes para crear modelos personalizados de aprendizaje automático y técnicas estadísticas para generar previsiones.
Para reproducir los ejemplos del artículo, descarga aquí todos los archivos necesarios.
Análisis de previsiones temporales en Power BI
Como ya se ha mencionado, Power BI ofrece múltiples funciones avanzadas de análisis de datos. Entre las más interesantes se encuentra la previsión incorporada.
Esta herramienta permite realizar análisis predictivos de forma rápida y sencilla, manteniendo la misma granularidad de los datos. Si se necesita hacer una previsión sobre los próximos 30 puntos de datos, y por punto de datos se entiende «el día», entonces los registros que constituyen el historial deben contener la medida a prever (valor numérico) con el nivel de detalle del día. Si, por el contrario, por punto de datos se entiende «la semana», entonces éste será el nivel de detalle necesario para realizar la predicción.
En resumen , se trata de una previsión con el mismo nivel de granularidad que el punto de datos utilizado. Tras importar el conjunto de datos, el análisis temporal mediante la opción incorporada implica el uso de un gráfico de líneas, ya que es esencial disponer de una referencia temporal continua en el eje x. En el eje y se introducirá la medida agregada, con respecto al nivel de granularidad del punto de datos, para el que queremos calcular la previsión.
Las características del conjunto de datos deben ser las siguientes:
- El eje X muestra valores continuos y uniformemente crecientes (véase la granularidad de los puntos de datos) con tipo de datos: fecha o fecha/hora
- El gráfico de líneas debe contener una sola medida, por lo que no puede contener varias «líneas».
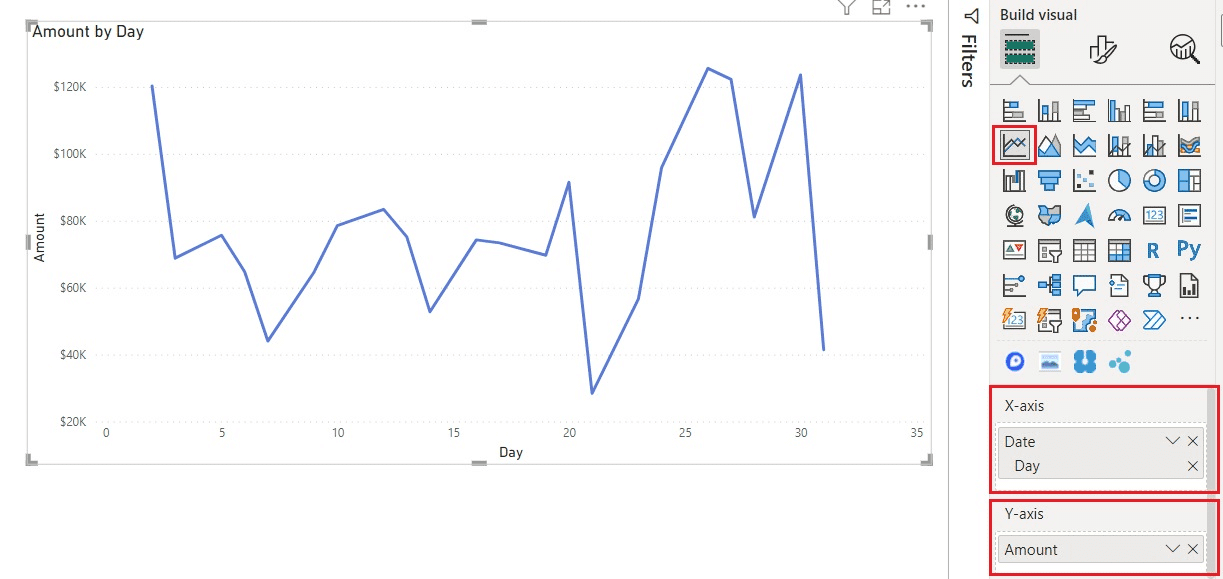
Para habilitar la opción de previsión, seleccione el tercer icono en » Analytics » y, a continuación, active la opción » Forecast «. Es importante tener cuidado de que se den las condiciones adecuadas para habilitar esta opción, ya que la previsión no está disponible si Power BI no detecta ninguna fecha en el gráfico.
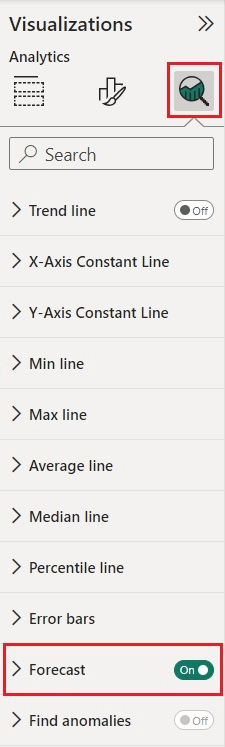
El análisis predictivo de Power BI incluye varios parámetros que pueden configurarse para modificar el resultado final:
UNITS: las unidades se utilizan para determinar si la previsión debe hacerse en años, trimestres, días o cualquier otra opción disponible en función del tipo de fechas del gráfico.
FORECAST LENGTH: corresponde a la duración de la predicción. Puede decidir el número de unidades que desea pronosticar. En este ejemplo, utilizamos una longitud de previsión de 15, lo que significa que haremos una previsión de 15 unidades, es decir, 15 días.
IGNORE THE LAST: opción con la que puede especificar qué valores -y puntos de datos correspondientes- ignorar cuando considere que determinados intervalos de tiempo no deben incluirse en el análisis de previsiones porque están asociados a datos que se consideran poco significativos a efectos de análisis. Por ejemplo, una empresa puede optar por ignorar las ventas del mes de agosto porque las considera poco representativas dados los numerosos días festivos en los que la empresa permaneció cerrada.
SEASONALITY: La estacionalidad es una opción de Power BI que se utiliza para determinar ciertas tendencias a lo largo de un periodo determinado. Detecta ciertas variaciones a lo largo del año. Es el periodo en el que un determinado patrón se repite varias veces dentro de la duración de la previsión. No puede ser superior al número de unidades del gráfico. Cuanto mayor sea el historial de datos en relación con el número de unidades a pronosticar, mayor será la capacidad de Power BI para realizar pronósticos más precisos.
CONFIDENCE INTERVAL: Por último, tenemos el intervalo de confianza. Se trata de un intervalo que representa la estimación de un parámetro. Aunque se expresa en forma de porcentaje (por ejemplo, 95%), no significa que exista una probabilidad del 95% de que el parámetro se encuentre dentro de los dos extremos del intervalo. Un intervalo de confianza del 95% significa que si se repitiera la predicción, en el 95% de los casos el intervalo contendría el valor verdadero. El intervalo de confianza se utiliza, en otras palabras, para determinar la fiabilidad del valor. Un intervalo de confianza pequeño aumenta la probabilidad de que el valor verdadero no se encuentre dentro de los extremos del intervalo porque la estimación se hace más precisa. A la inversa, aumentar el intervalo de confianza aumenta la probabilidad de encontrar el intervalo correcto para el valor verdadero, pero disminuye la precisión de la estimación.
En la imagen siguiente, puede ver un ejemplo de utilización del análisis de previsiones en Power BI aplicando determinados parámetros. La línea de puntos representa los valores Importe pronosticados mientras que la banda azul representa el margen de confianza establecido por el valor del rango porcentual elegido.
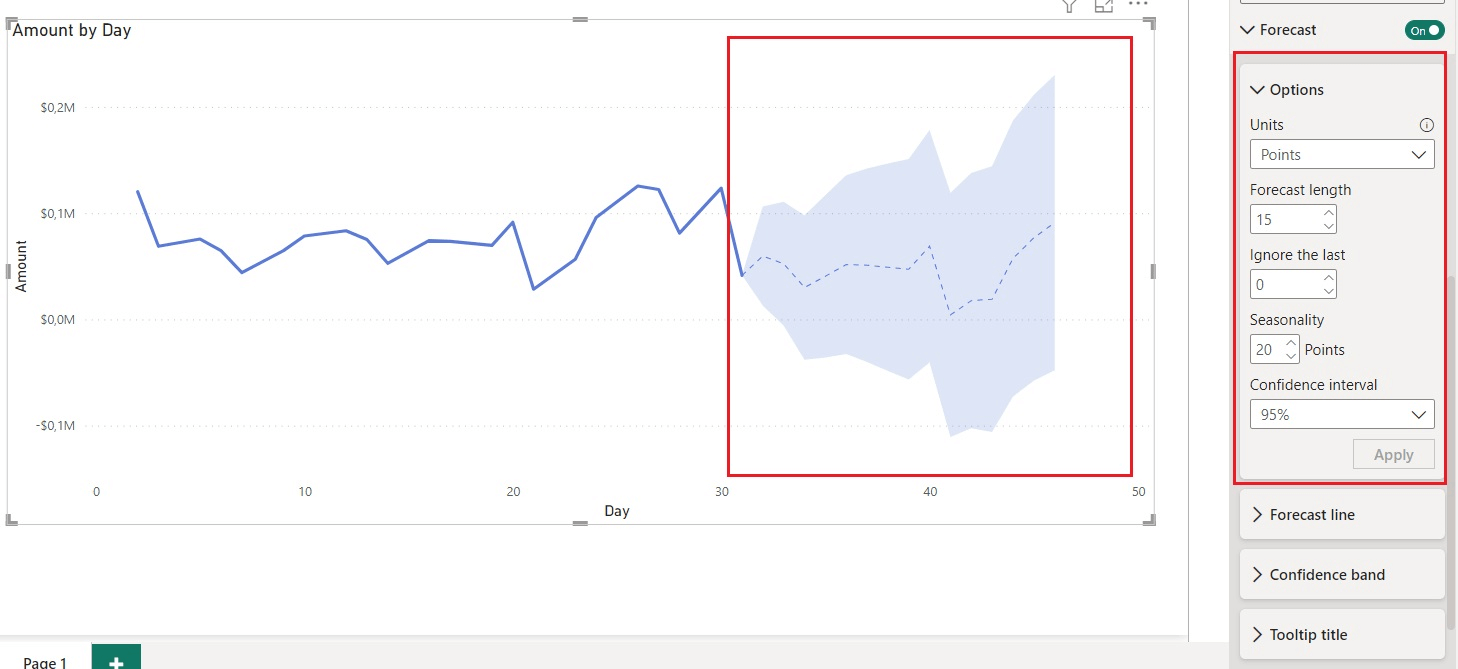
La previsión en Power BI se basa en un algoritmo de previsión muy complejo llamado Suavizado Exponencial. Para ser precisos, existen dos modelos de Suavizado Exponencial: Datos Estacionales (ETS AAA), que tiene en cuenta las tendencias y la estacionalidad aditiva, y Datos No Estacionales (ETS AAN), un modelo más sencillo que solo considera las tendencias.
El modelo ETS AAA también se conoce como algoritmo Holt-Winters. Es el más complejo de los dos porque busca los parámetros óptimos para minimizar la desviación cuadrática media (MSE) en las previsiones del modelo de entrenamiento, teniendo en cuenta no sólo las previsiones «más cercanas» sino también las que tienen un horizonte temporal más largo, con el fin de reducir la varianza y preservar la tendencia. Esencialmente, el modelo aplica una media ponderada de las observaciones históricas, dando más peso a las observaciones recientes que a las más remotas.
En ambos casos, Power BI aplica automáticamente el mejor algoritmo en función de los datos disponibles.
Para reproducir el ejemplo, consulte el libro de trabajo de Power BI «PBI Forecast built-in and Script R.pbix» incluido en la carpeta «1_example» que ha descargado.
Ampliaciones suplementarias para el Forecast
Power BI ofrece la posibilidad de utilizar librerias y herramientas R y Python como extensiones adicionales a las herramientas existentes. Para ambos lenguajes de programación se dispone de visuales específicos que permiten la introducción directa de código para crear gráficos personalizados, que luego pueden incorporarse fácilmente a los cuadros de mando de Power BI.

Al seleccionar el icono de uno de estos objetos visuales en el panel de visualización de Power BI, se genera un nuevo elemento en el espacio de trabajo y se abre el editor dedicado para introducir el código necesario para desarrollar el modelo de previsión. Para integrar los datos en su script R, basta con arrastrar y soltar los campos de interés en la sección «Valores» del panel de configuración de la visualización, siguiendo el mismo procedimiento que para cualquier otro elemento visual de Power BI. Es importante tener en cuenta que sólo los campos introducidos en esta área serán accesibles y utilizables en el script R.
N.B Ciertos prerrequisitos son necesarios para poder utilizar R y/o Python dentro de Power BI. Debe asegurarse de que ha instalado correctamente R y/o Python en su ordenador local, así como las bibliotecas y paquetes necesarios para el análisis. Además, deberá habilitar el scripting de R y/o Python en Power BI Desktop en Opciones de Archivo > Configuración > Opciones > Global seleccione Script R o Script Python dependiendo de lo que desee habilitar. Asegúrese de que la instalación local de R y/o Python se especifica en el directorio de inicio correcto.
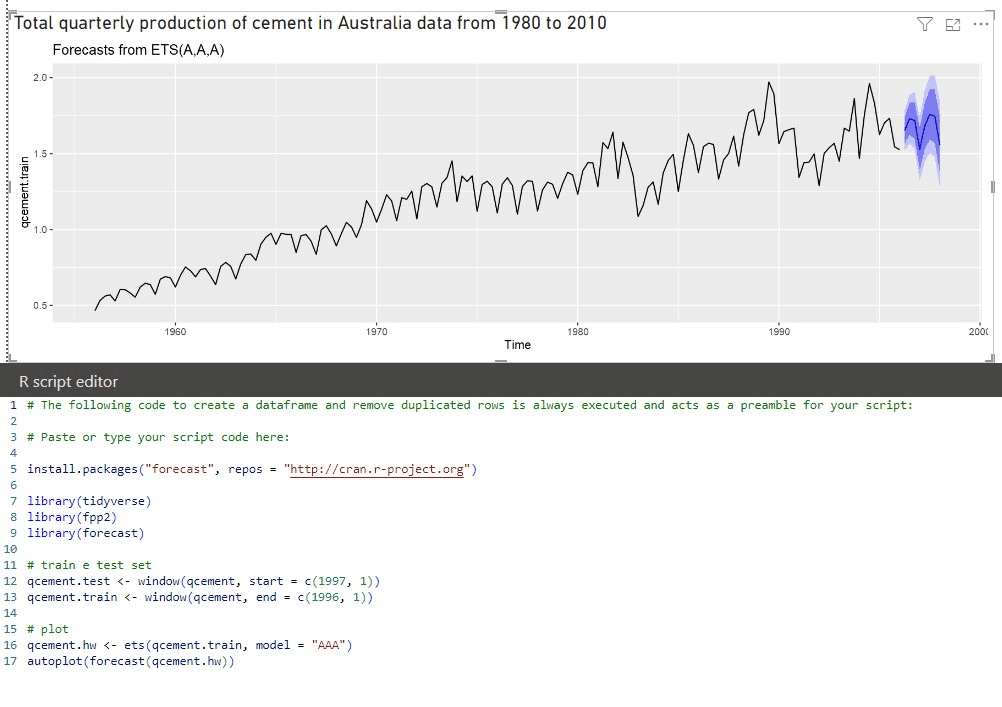
En el ejemplo anterior, importamos las bibliotecas que contienen las funciones necesarias para aplicar un modelo de predicción basado en el algoritmo de Exponential Smoothing, el mismo que se utiliza en Power BI. Utilizando un conjunto de datos de muestra, dividimos la muestra para entrenar el conjunto de entrenamiento y el conjunto de prueba con la función «window». Es una buena práctica reservar alrededor del 70% para el conjunto de entrenamiento (train set), es decir, la parte de los datos que se utiliza para entrenar el modelo para que haga predicciones precisas. El 30% restante se utiliza para el conjunto de validación (conjunto de prueba), es decir, una porción separada de datos no utilizada en la fase de entrenamiento que se utiliza para evaluar el rendimiento final del modelo en términos de su capacidad de predicción sobre nuevos datos. Por este motivo, al primero le asignamos fechas comprendidas entre 1956 y 1996 (40 años), mientras que al segundo le asignamos fechas comprendidas entre 1997 y 2014 (17 años, aproximadamente el 30% del conjunto de datos disponible).
Después de dividir los conjuntos de entrenamiento y validación, es necesario especificar qué algoritmo utilizar (ETS significa ‘Exponential Smoothing’, línea 16) asignando con el parámetro ‘model’ el método utilizado por el marco: la primera letra especifica el ‘error type’, la segunda el ‘trend type’, y la última el ‘season type’. En nuestro caso, ‘AAA’ identifica un dato estacional de suavizado exponencial con error aditivo, tendencia aditiva y estacionalidad aditiva.
Los diferentes trazos de color alrededor de la línea de previsión producida por nuestro modelo en R muestran los dos intervalos de confianza establecidos por defecto por R si no se especifican valores diferentes: 80% (morado oscuro) y 95% (morado claro).
En este caso, no aplicamos ningún parámetro especial al modelo que hubiera producido un resultado más preciso. En general, los pasos de entrenamiento y validación del modelo sobre los datos del conjunto de prueba son iterativos, es decir, se repiten varias veces tratando de encontrar la mejor combinación de parámetros para obtener una predicción más realista.
De nuevo, por favor replica el ejemplo del libro de trabajo de Power BI “PBI Forecast built-in e Script R.pbix”.
Comparación de las técnicas de análisis predictivo en Power BI
Supongamos en este punto que queremos comparar las previsiones producidas confiando en la opción incorporada en Power BI Desktop con modelos estadísticos cuyos parámetros pueden ser especificados por el usuario ejecutando scripts Python directamente en Power BI. Como ya se ha mencionado, la capacidad de ejecutar código Python o R es la base de las extensiones incorporadas para la previsión.
A continuación, se presentará una comparación cualitativa entre el valor actual ( Actual value), el valor pronosticado con la opción nativa e integradora (PBI Forecast) y los pronósticos calculados entrenando dos modelos basados en: SARIMA y Holt-Winters. El conjunto de datos del que partimos recopila transacciones de ventas día a día durante un lapso de tiempo de unos cuantos años a partir de 2017. Esta es la configuración del ejemplo:
Dataset:
- Conversión de fechas en notación mm/dd/aaaa
- Granularidad diaria, por lo que las ventas se agregan (suman) a nivel diario.
- Training set, formado por los datos del periodo 01/01/2019 – 31/12/2019
- Valores reales establecidos, consistentes en datos en el intervalo de tiempo 01/01/2020 – 31/03/2020
- Visibilidad pública
Para poder reproducir el ejemplo, busque en la carpeta »2_esempio»:
El archivo pdf Istruzioni_e_Script_Python.pdf, contiene las instrucciones para crear el entorno virtual y la configuración en Power BI Desktop. También contiene el código básico para el ajuste de modelos que se pueden importar con la librería StatsModels de Sci-kit learn.
El dataset EXTRACT.csv, que contiene las ventas y el día en que se produjeron – se trata de una extracción del conjunto de datos Contoso distribuido gratuitamente por Microsoft.
El dataset Sum of Sales Amount by Date.csv, que contiene la proyección de ventas calculada con la funcionalidad de previsión incorporada en Power BI Desktop. Se utiliza para mostrar en el cuadro de mando una comparación entre las previsiones calculadas por los distintos modelos.
El workbook PowerBI Analisi_Predittive_a_Confronto.pbix, contiene el código de desarrollo del informe.
En Power BI, el script Python que manipula los datos lo hace apuntando a una estructura de datos de tabla de la librería Pandas, el DataFrame, que por defecto se referencia a través de la variable dataset. Esta información es muy importante tenerla en cuenta a la hora de escribir el código, ya que sólo estas estructuras de datos específicas pueden ser almacenadas y accedidas por el entorno ETL de Power Query. Para ello, optamos por ejecutar el script de Python como un paso en Power Query y, a continuación, acceder al DataFrame que contiene el resultado de la previsión.
La serie de ventas analizada muestra una tendencia débil y una tendencia estacional, que no están directamente influenciadas por el paso del tiempo. Por tanto, pensamos en utilizar los dos modelos probados (el proceso de estimación de los hiperparámetros queda fuera del alcance):
- SARIMA (Seasonal AutoRegressive Integrated Moving Average) es la extensión del modelo ARIMA para series temporales con un componente estacional.
- Holt-Winters o Nivelación exponencial (similar a lo que propone Power BI de forma nativa) con un modelo aditivo.
El informe consta de dos páginas:
- “Actual + Forecasting” muestra 3 gráficos de líneas diferentes, que muestran la tendencia de las ventas en el histórico, después en el conjunto de entrenamiento (las series históricas con las que se ajustaron los modelos mediante código Python o a través de la función integrada de Power BI Desktop), seguidos de las previsiones calculadas.
- “Forecasting” muestra la comparación en el mismo gráfico (activado por selección) de valores:
- PBI Forecast, predicción con la opción integrada de Power BI Desktop
- SARIMA, predicción con el modelo del mismo nombre
- Holt-Winters, pronosticado con el modelo del mismo nombre
- y comparado con el valor esperado, Valores reales
Teniendo en cuenta factores secundarios como el conocimiento de los modelos y las técnicas de estimación de valores no ideales de los hiperparámetros, el análisis predictivo realizado por Power BI Desktop es de buena calidad y ventajoso por su bajo coste operativo. Esto hace de Power BI una buena herramienta, a pesar de la limitación de no poder acceder directamente a los valores predichos y sus intervalos de confianza, que sólo están disponibles exportando los datos del objeto visual.
Conclusiones
En conclusión, el forcasting en Power BI permite obtener información predictiva a partir de un conjunto de datos históricos que ya se poseen. Existen varias herramientas que pueden realizar análisis de previsión, dependiendo de la distinta naturaleza orientada al usuario de la herramienta.
Descubre nuestras soluciones Power BI
A tu lado, desde la consultoría a la formación, pasando por las soluciones de visualización de datos.

Visualitics Team
Este artículo ha sido escrito y editado por uno de nuestros consultores.
Fuente:
- Describing the forecasting models in Power View: www.powerbi.microsoft.com
- ETS: Exponential Smoothing state space model, R Documentation: www.rdocumentation.org
- Exponential Smoothing in R Programming, GeeksforGeeks: www.geeksforgeeks.org
- Holt-Winters: www.statsmodels.org
- How to Forecast Data in Power BI, SQL Server Central: www.sqlservercentral.com
- Pandas DataFrame: pandas.pydata.org
- Python: www.python.org
- SAS, Analisi Predittiva: www.sas.com
- SAP, What is Predictive Analysis?: www.sap.com
- SARIMA: www.statsmodels.org
- Time Serie Forecasting with R (Part 2), Medium: www.medium.com
- Venv: www.docs.python.org
Compártelo ahora en tus redes sociales o por correo electrónico:
