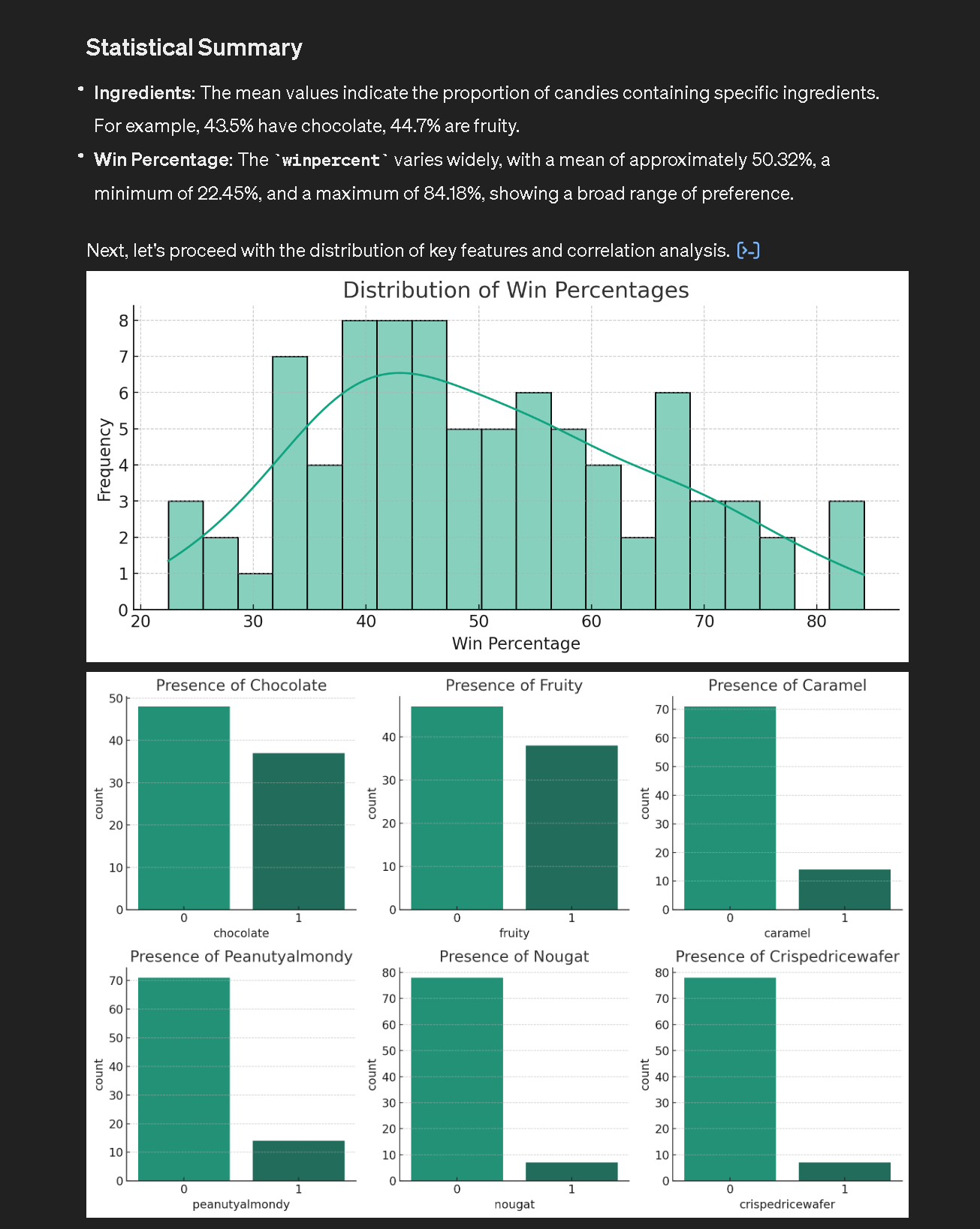
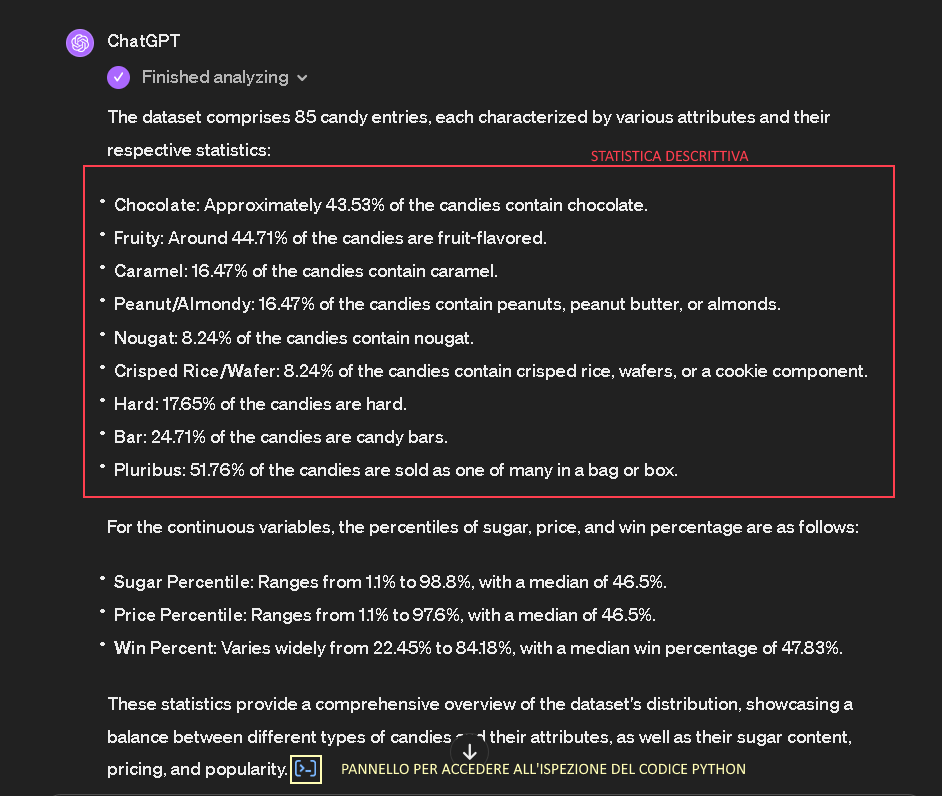
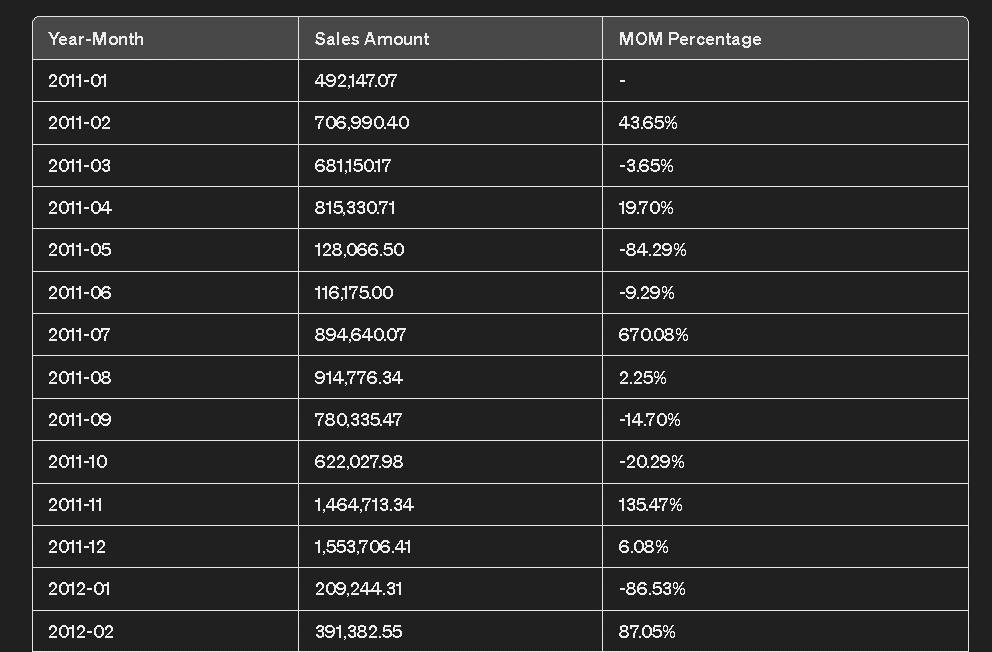
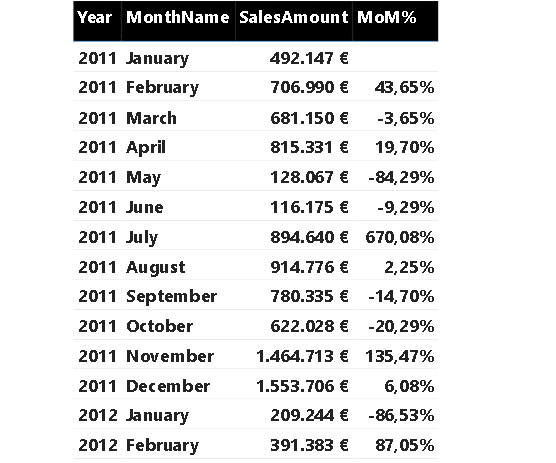
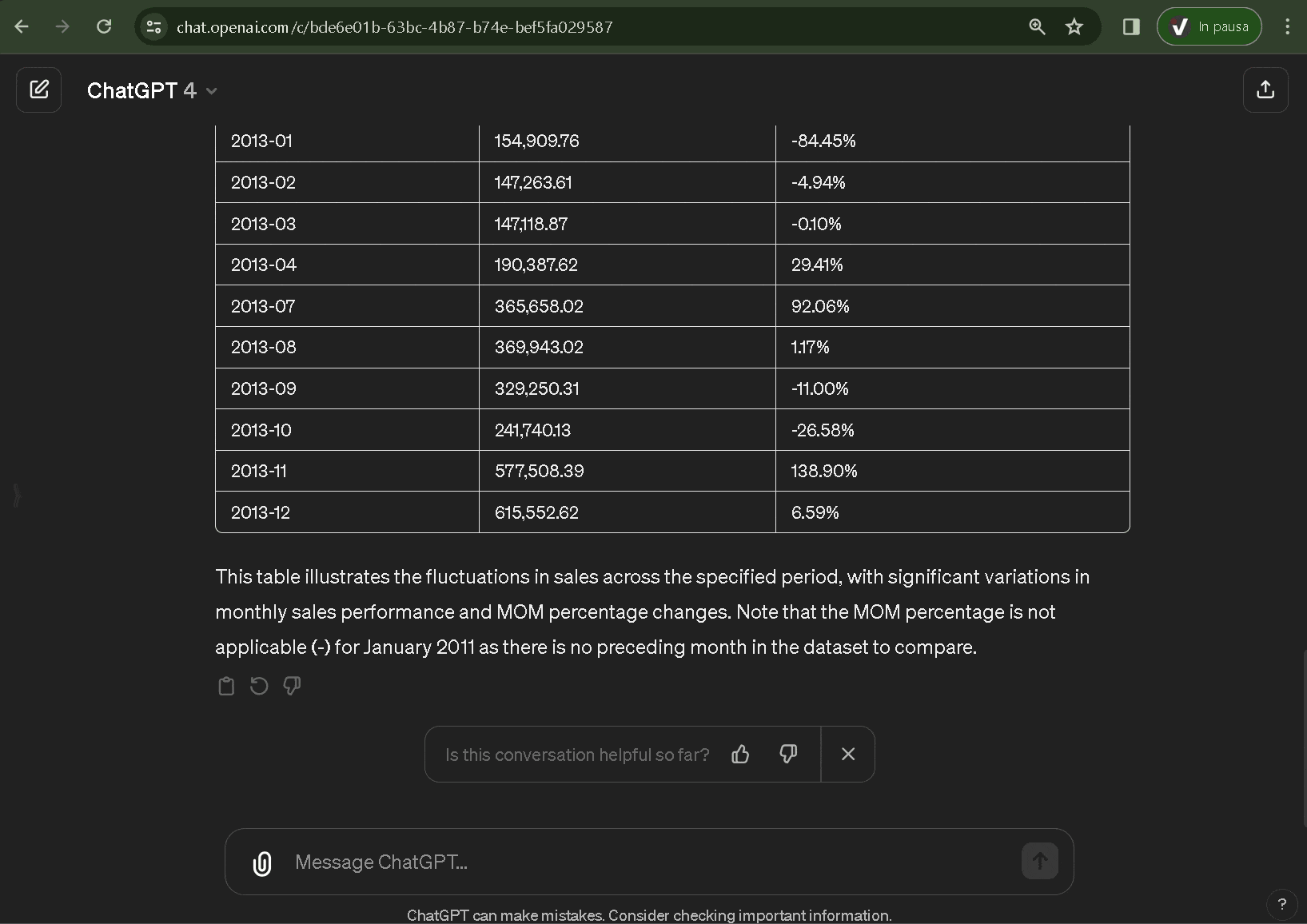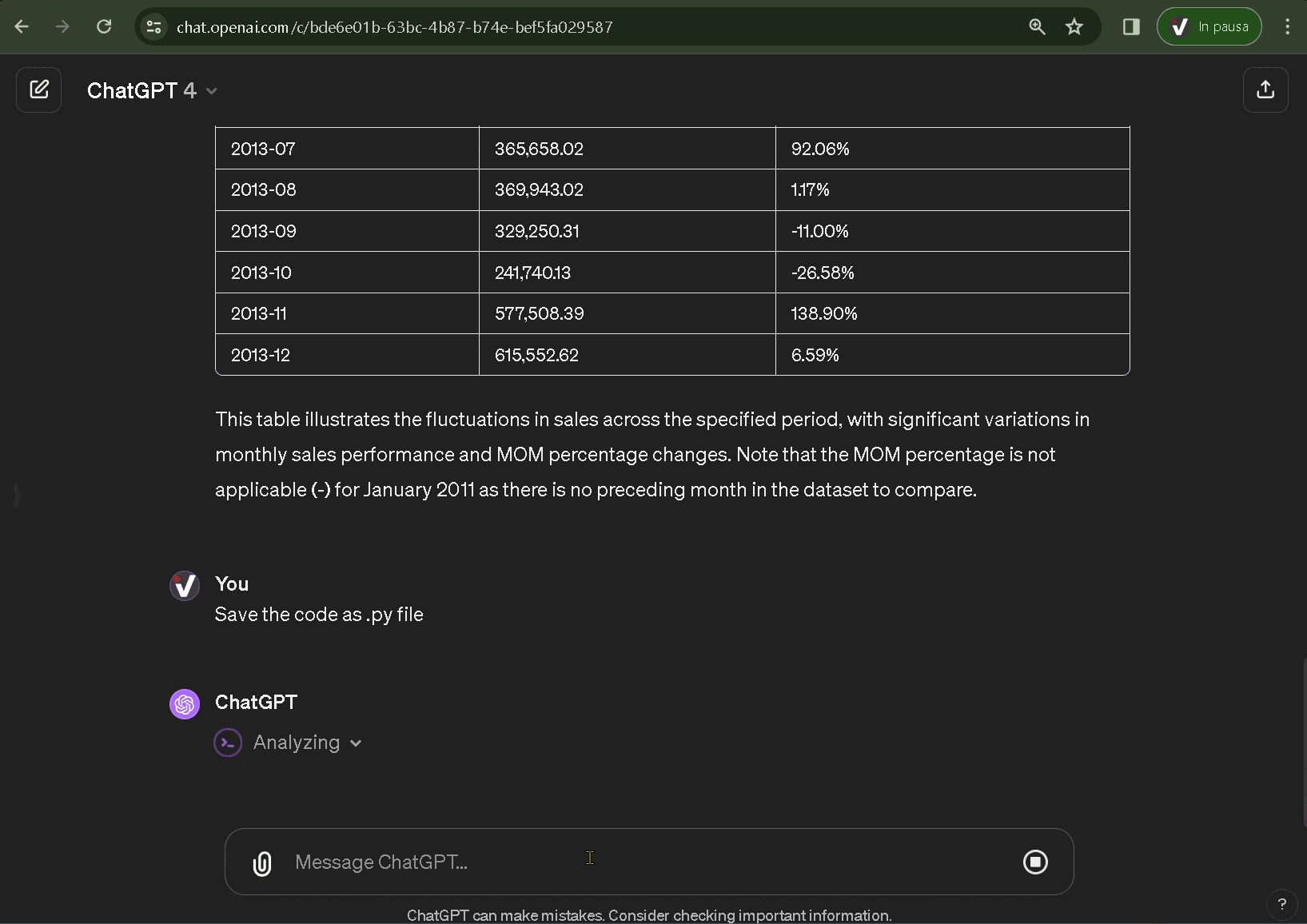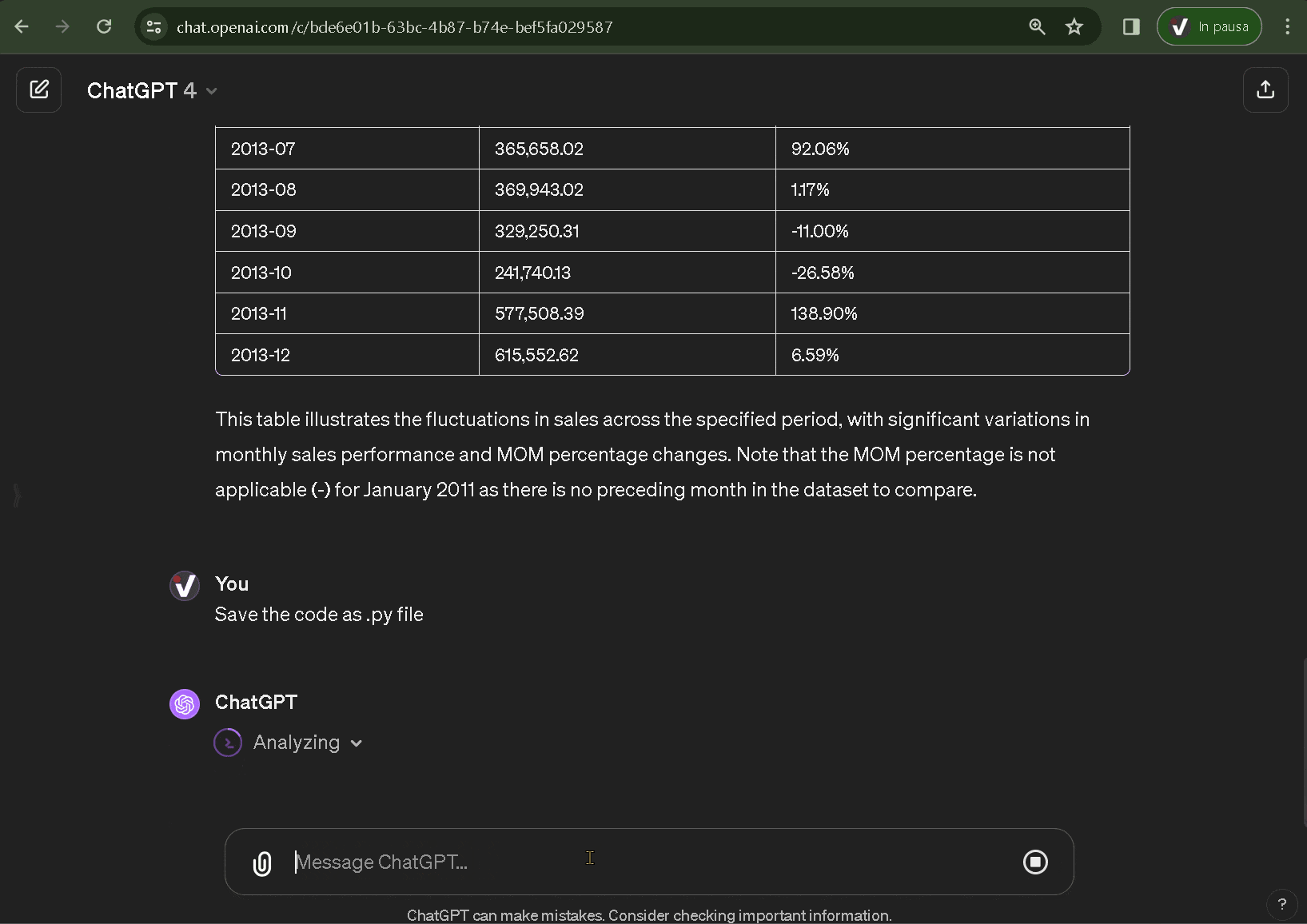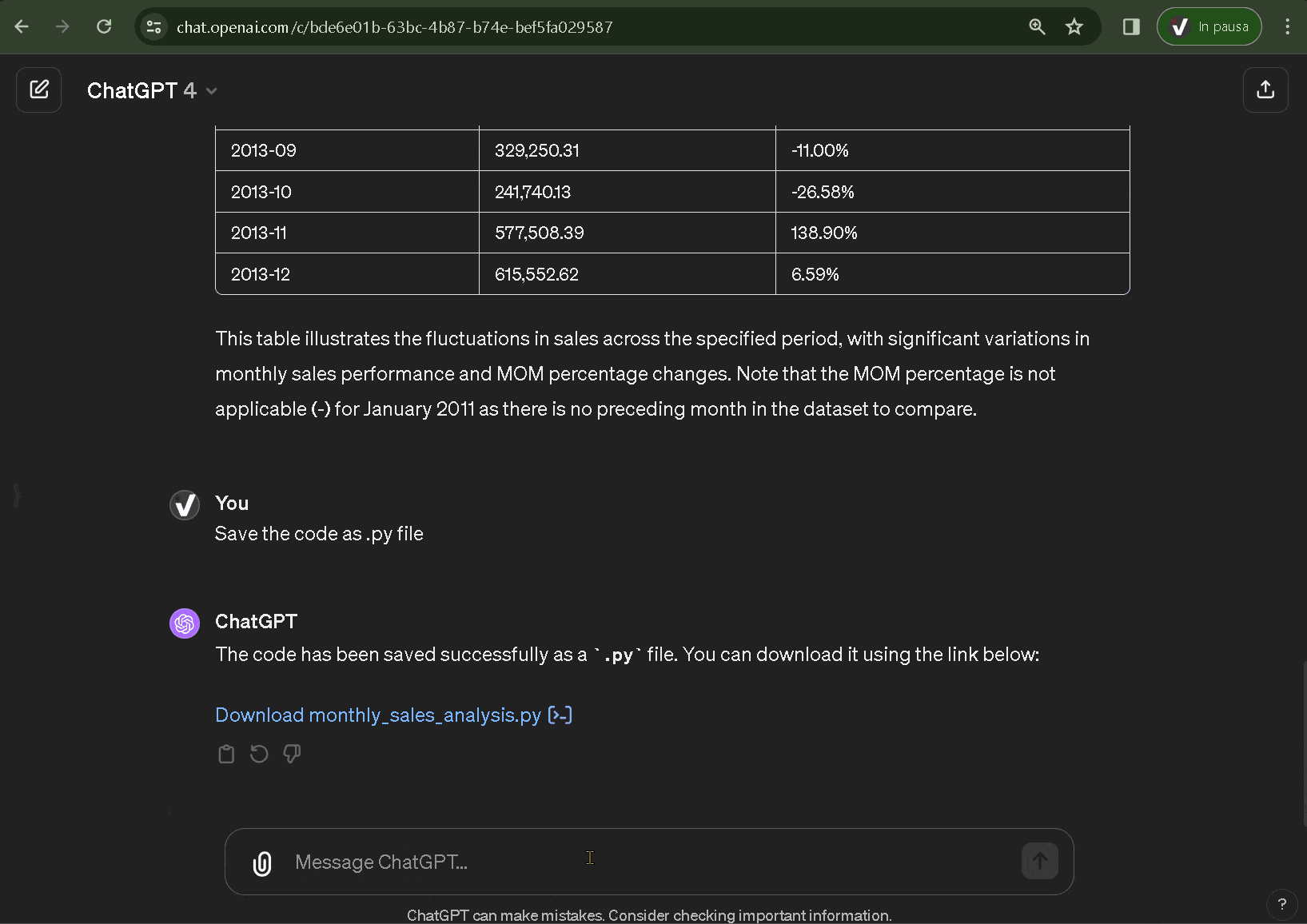
Imaginemos ahora un contexto de utilización diferente, pero mucho más frecuente, con un conjunto de datos del que sólo se conocen las generalidades. Es útil realizar una primera fase de análisis para conocer, por ejemplo, la cardinalidad, el tipo de datos y su distribución. Pero también para poner de relieve posibles errores o datos incompletos, o correlaciones o patrones que se investigarán en fases posteriores.
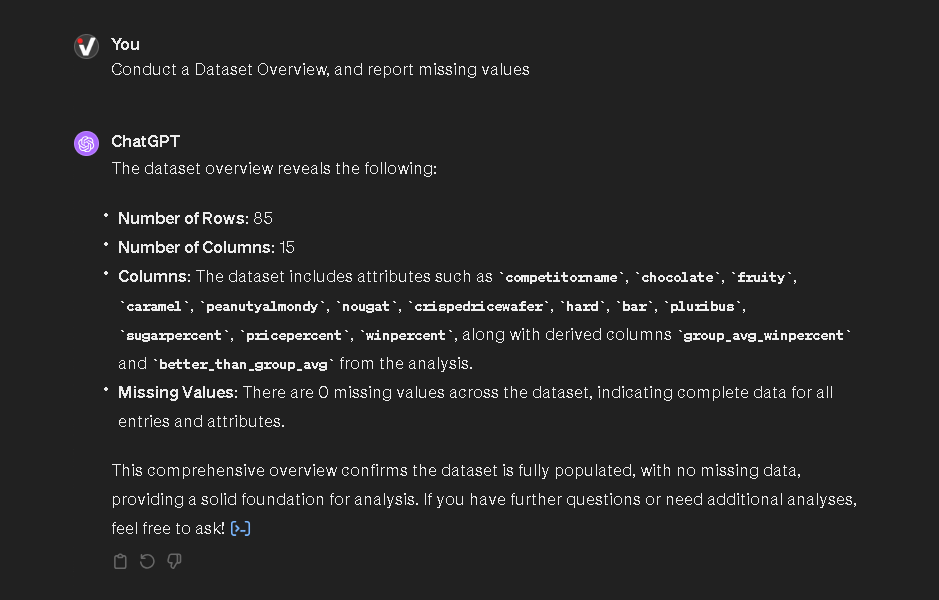
El primer paso comienza con el EDA. Para este ejemplo, utilizamos un conjunto de datos con las valoraciones de los dulces de Halloween y procedimos a:
- Cargar el conjunto de datos especificando cómo interpretar el contenido textual, gracias a la descripción en Kaggle, para solicitar un análisis estadístico descriptivo.
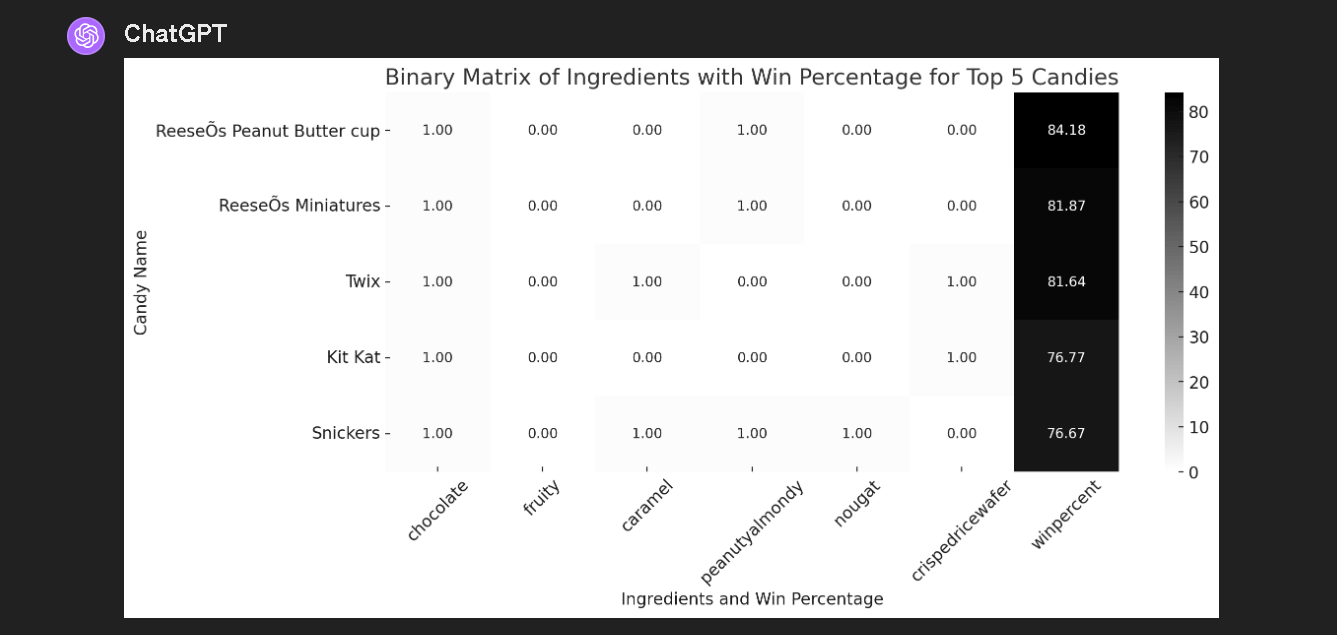
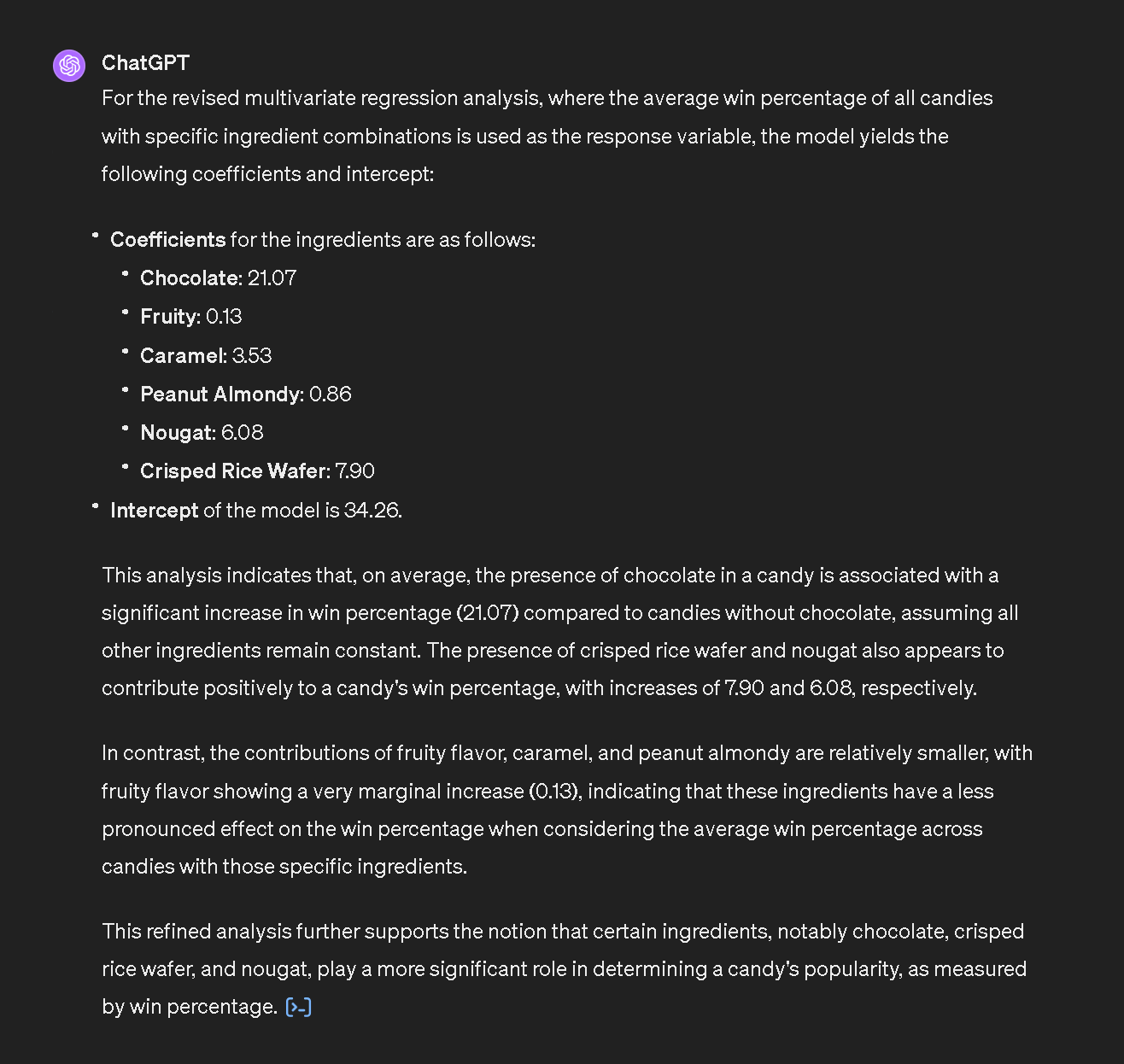
- Evaluar los resultados y solicitar otros niveles de análisis o insights.
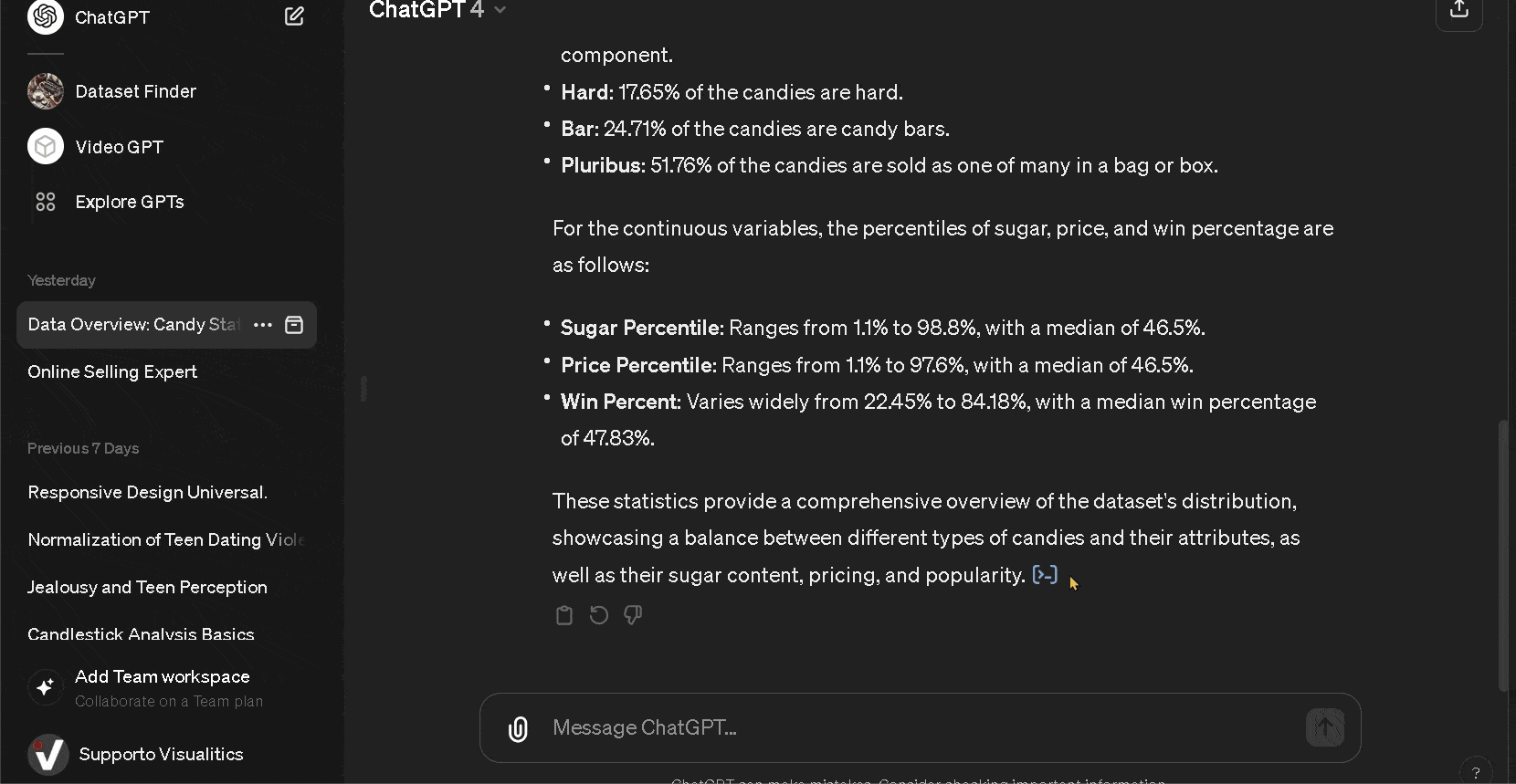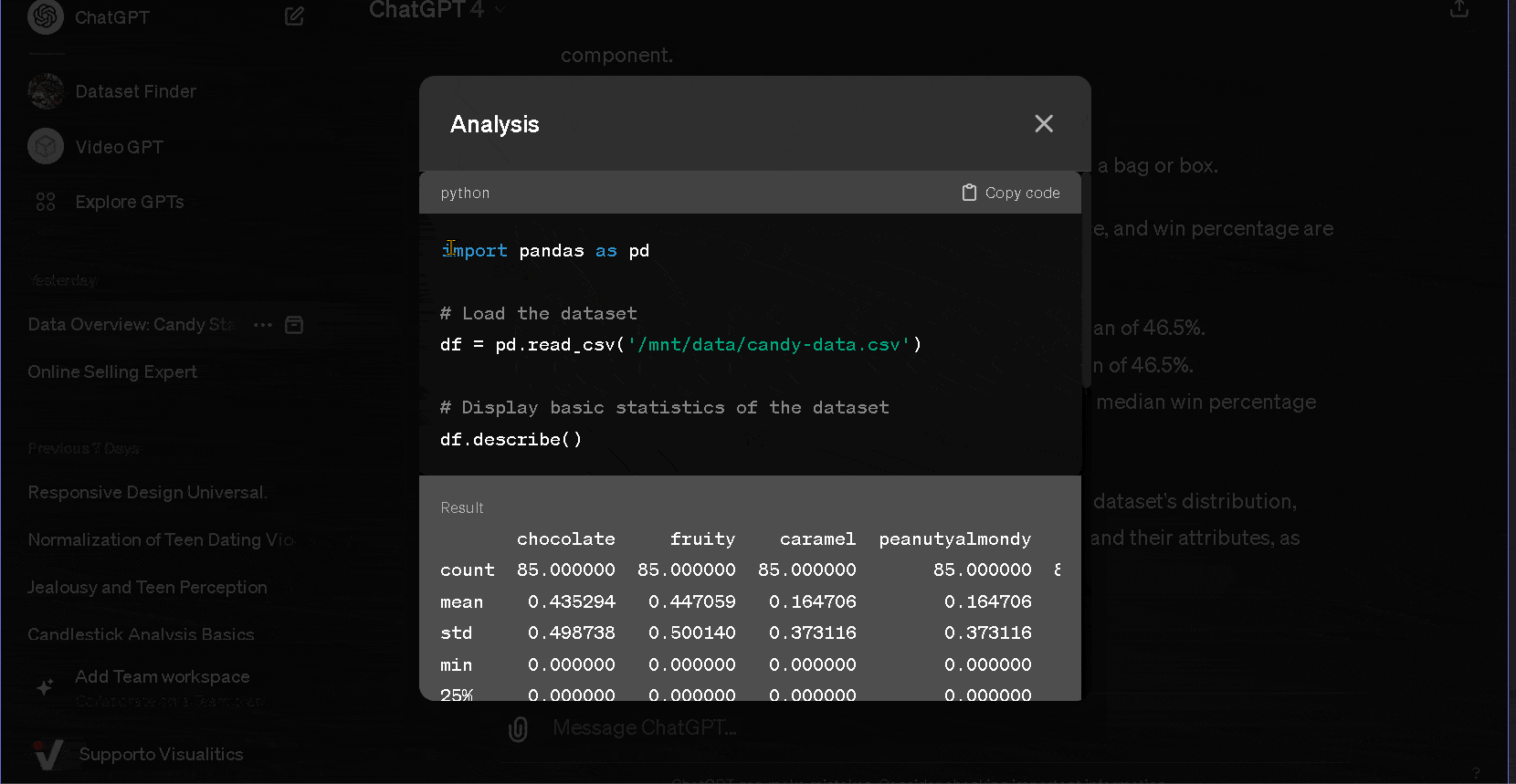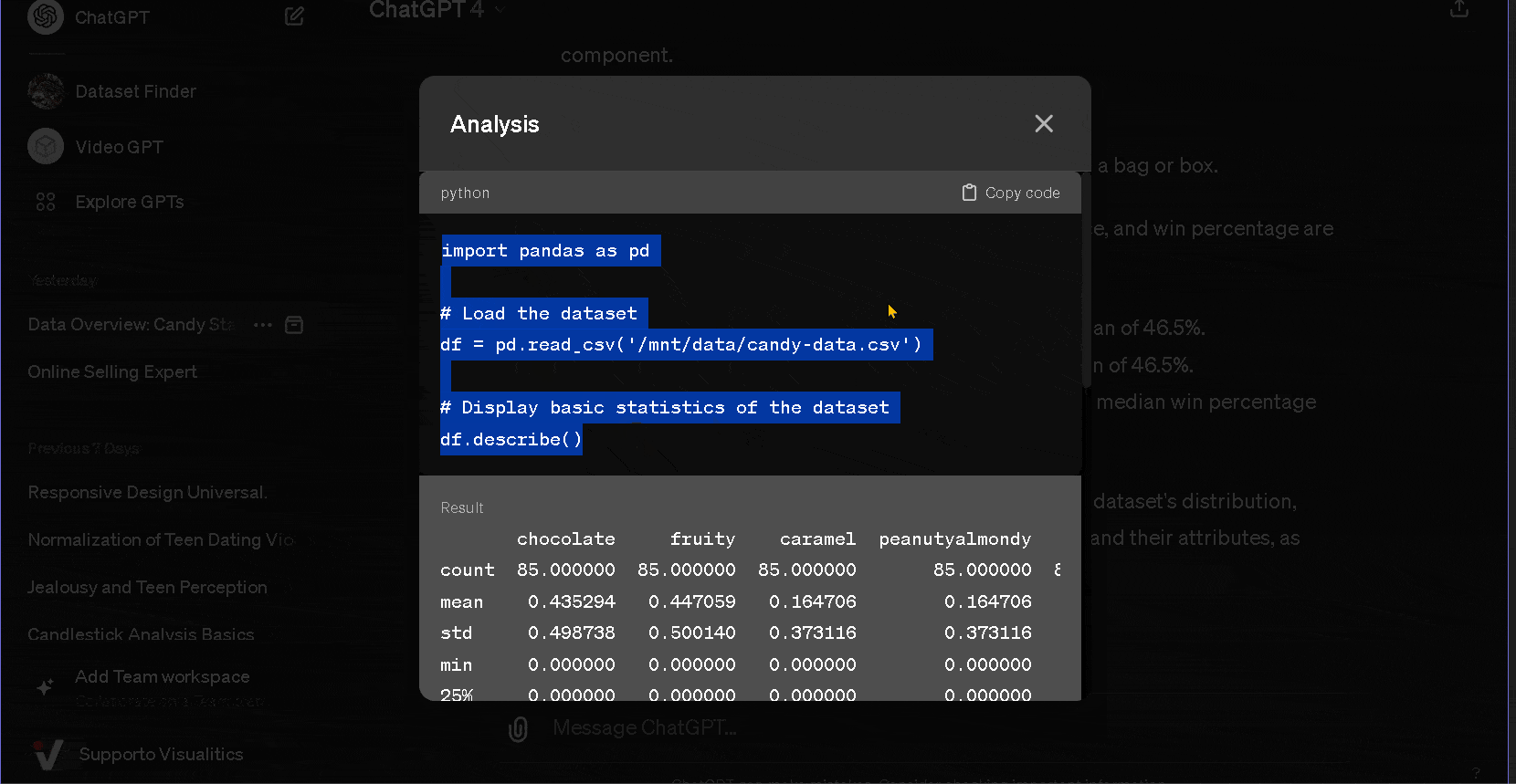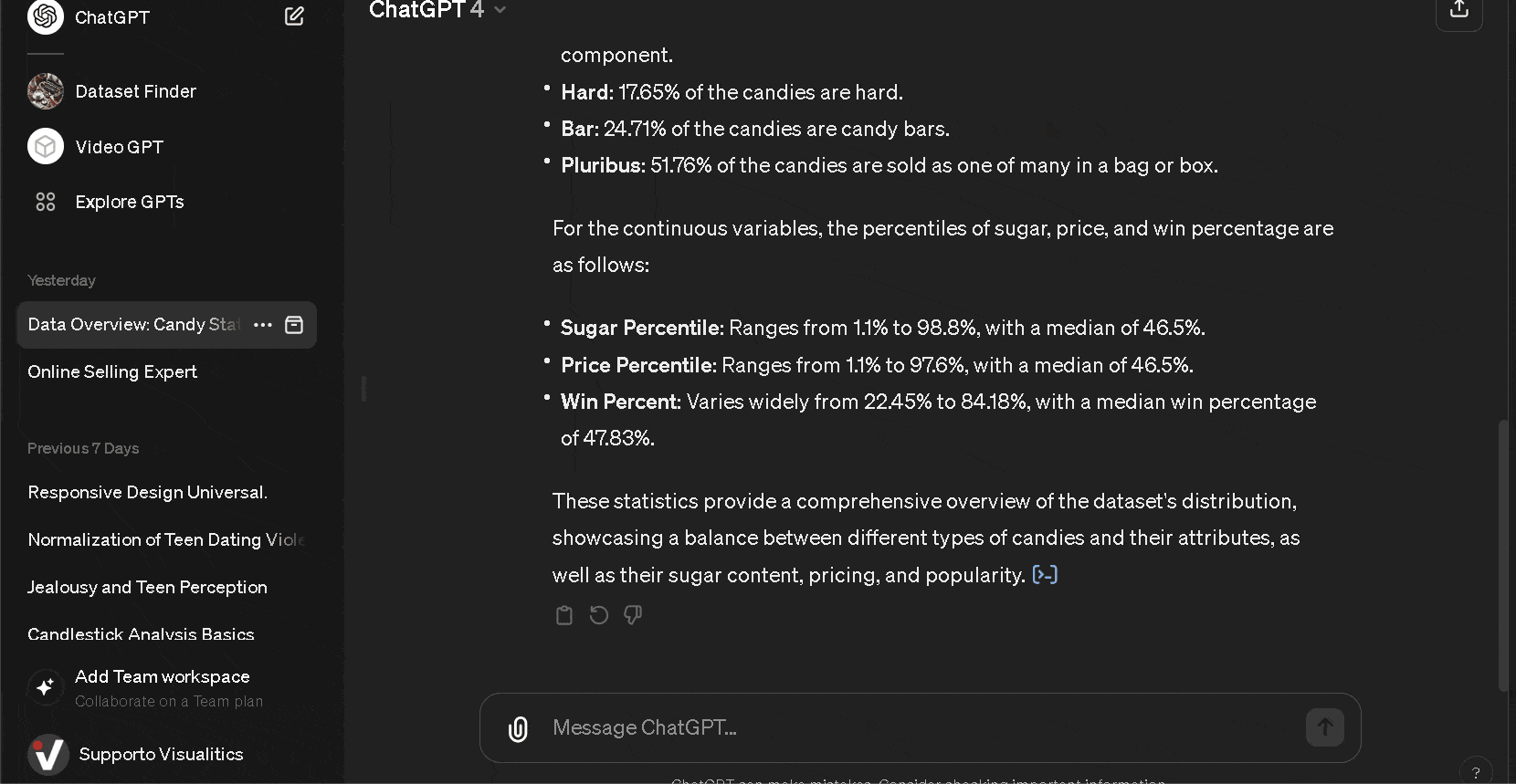
- Exportar el código obtenido y continuar el análisis de forma comparativa y/o en profundidad.
El siguiente gif refleja el flujo de trabajo descrito en los puntos anteriores: